AWS Outage
AWS Outage
AWS, or Amazon Web Services, provides a variety of cloud computing services. Many businesses rely on these services for their operations. When AWS experiences an outage, it can have significant impacts.
Understanding the causes of AWS outages is important. There are several potential reasons. These can range from hardware failures to software bugs to human error. Each incident is unique, and the effects can vary widely.
Hardware Failures
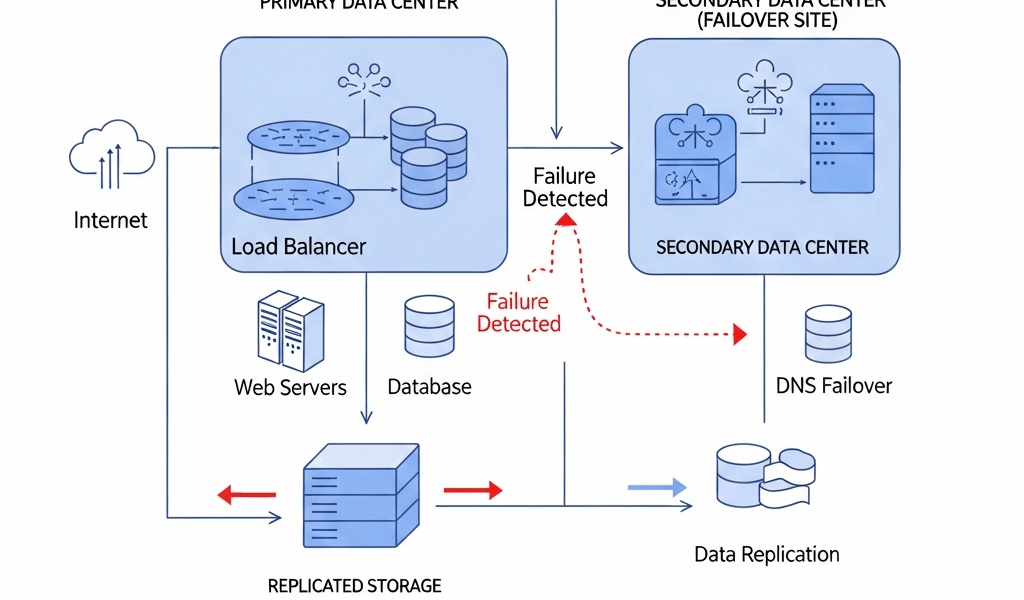
AWS has data centers all over the world. These data centers contain thousands of servers. Hardware failures can occur for many reasons. Power failures, network issues, and aging equipment can all contribute to these failures. AWS has redundancy in place to minimize the impact, but outages can still occur.
Software Bugs
Software bugs are another common cause of outages. AWS uses complex software to manage its infrastructure. Bugs in this software can cause severe disruptions. Even minor bugs can have major effects when they occur in critical systems. AWS continuously updates and patches its systems to fix bugs, but some issues can still slip through.
Human Error
Human error is a contributing factor in many outages. Mistakes can happen during routine maintenance or updates. These mistakes can lead to system failures and downtime. AWS has procedures in place to minimize human error, but it cannot be completely eliminated.
Impact on Businesses
When AWS experiences an outage, the impact on businesses can be profound. Many companies rely on AWS for their websites, applications, and data storage. An outage can mean lost revenue, reduced productivity, and damage to reputation. Businesses often have contingency plans in place, but an outage can still be disruptive.
- Website downtime
- Application failures
- Data access issues
These effects can be damaging, especially for businesses that rely heavily on technology. Downtime can lead to loss of customers and decreased trust. It can also affect internal operations, making it difficult for employees to do their jobs.
Case Studies of Major AWS Outages
Looking at past incidents can provide valuable insights. Each outage teaches us something new about the complex nature of cloud computing. Here are a few notable cases:
March 2018 S3 Outage

In March 2018, AWS S3 experienced a significant outage. S3, or Simple Storage Service, is a fundamental part of many web services. The incident was caused by an incorrect command entered during a routine maintenance operation. This error took down several essential servers, leading to widespread disruption.
November 2020 Outage
An AWS outage in November 2020 affected many services. Elastic Compute Cloud (EC2) and Relational Database Service (RDS) were among those impacted. The root cause was an issue with the Kinesis Data Streams service. This problem created a domino effect, causing failures across multiple AWS services. Many high-profile websites and applications experienced downtime.
June 2021 Outage
In June 2021, AWS experienced another significant outage. This time, the root cause was a configuration change to the Amazon Route 53 service. This change inadvertently affected the ability of end-users to resolve domain names, leading to widespread impact. Many services that relied on domain name resolution were affected, causing website outages and access issues.
Preventive Measures and Improvements
AWS continuously improves its infrastructure to prevent outages. This includes regular updates, patches, and expanding redundancy capabilities. AWS also invests in robust monitoring and automated recovery mechanisms. These efforts help to detect and resolve issues more quickly. However, no system is foolproof, and occasional outages are inevitable.
Businesses can also take steps to mitigate the risks associated with an AWS outage. Here are some strategies:
Strategies for Mitigating Risks
- Multi-Region Deployments: Deploying applications across multiple regions can provide resilience. If one region goes down, others can still operate.
- Data Backup and Recovery: Regularly backing up data ensures that it can be restored quickly in case of an outage.
- Monitoring and Alerts: Implement robust monitoring systems to detect issues early. Set up alerts to notify your team of potential problems.
- Disaster Recovery Plans: Develop and test disaster recovery plans. Ensure that your team knows what to do in the event of an outage.
Moving Forward with Cloud Computing
While AWS outages can be disruptive, cloud computing remains essential. The benefits of scalability, flexibility, and cost savings are significant. By understanding the causes and impacts of outages, businesses can better prepare and respond.



Stay in the loop
Get the latest web sme updates delivered to your inbox.